Overview

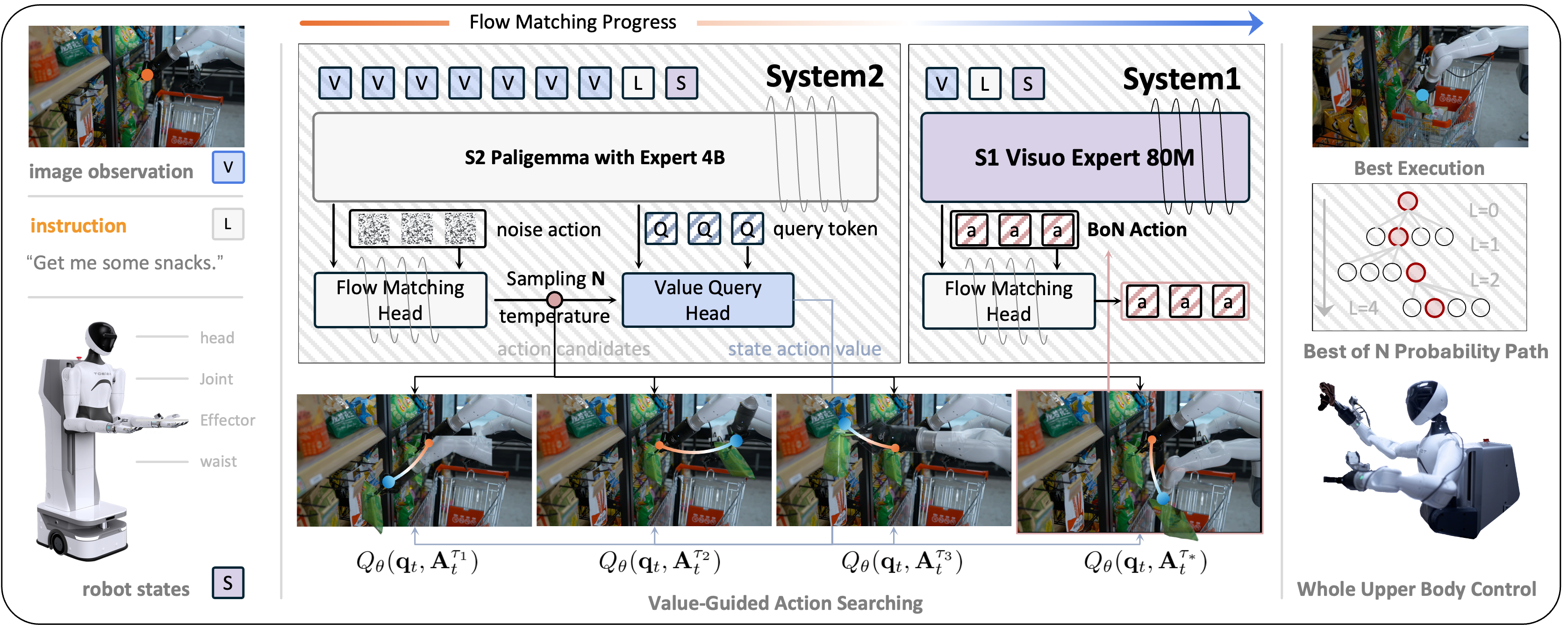
We present Hume, a dual-system vision-language-action model exploring human-like thinking capabilities for dexterous robot control. Equipped with value-guided System-2 thinking and cascaded action denoising, the model achieves superior complex reasoning and control capabilities. The model achieves state-of-the-art performance across a diverse range of evaluations and shows significantly advancement in complex robot control tasks.